

Power Up Your GKE Cluster with Node Labeling for Efficient Scheduling
By labeling worker nodes, you can ensure that specific workloads are scheduled on the appropriate nodes, improving resource utilization and operational efficiency.

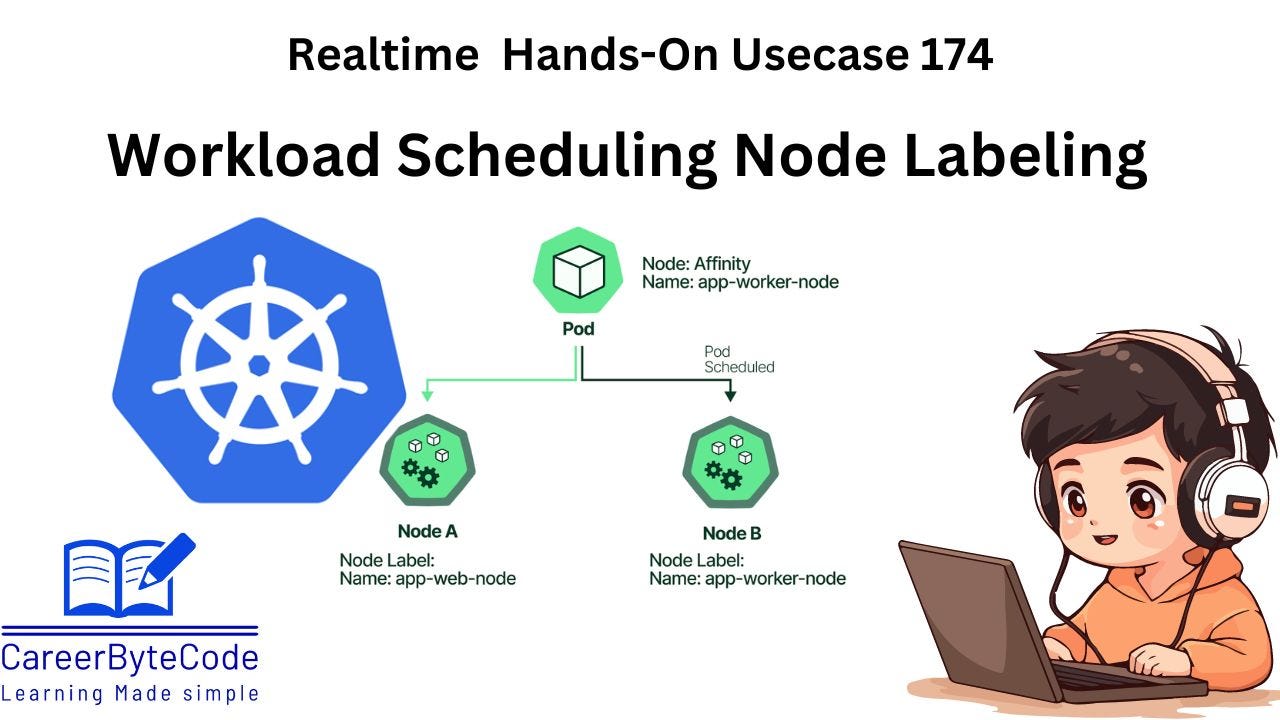
1. Why We Need This Use Case
In a Kubernetes environment, certain workloads might require specific hardware, network configurations, or resource allocations. By labeling worker nodes, you can ensure that specific workloads are scheduled on the appropriate nodes, improving resource utilization and operational efficiency. Node labeling allows Kubernetes to identify and assign workloads based on specific criteria, such as performance requirements or data residency constraints. This ensures the right workloads run on the right nodes, optimizing both cost and performance.
2. When We Need This Use Case
When workloads require specific hardware configurations (e.g., GPU-enabled nodes or nodes with high memory).
When you need to segregate workloads based on network, geographical region, or environment (e.g., production vs. development nodes).
For running performance-critical applications that must always be deployed on high-performance nodes.
When managing multi-tenant environments, and you need to isolate specific customers' workloads.
When you want to ensure that resource-heavy applications are scheduled on high-resource nodes, while smaller workloads can run on less powerful nodes.
